
The Ethics of Artificial Intelligence: What Kind of Society Do We Want to Have?
As someone who has worked with big data for some time, I have pushed the boundaries where this idea of relevance morphs into creepy — remember the infamous case study: How Target Figured out a girl was pregnant before her father did?
I am acutely aware of AI’s implications in digital marketing, its lure to big business, and at the same time, the fear it creates among consumers.
As data becomes more abundant and consumer digital footprints become commonplace, more understanding of their lives are analyzed and contextualized. The average consumer is becoming increasingly educated about what they share and how it’s used by business, many times without the user acknowledgment or consent.
AI is accelerating its pace and with it, the massive data sets allow analysis and contextualization of information that has inherent benefits… but also vulnerabilities to individuals and society, real and yet to be revealed.
In 2012 I wrote this post on my company blog Genx Think Tank: It’s all about Privacy. At that time, everyone agreed that use of social platforms is a fair exchange of user data collection. Julie Bernard, CMO of Macy’s said,
There’s a funny consumer thing… They’re worried about our use of data, but they’re pissed if I don’t deliver relevance. … How am I supposed to deliver relevance and magically deliver what they want if I don’t look at the data?
Some more sophisticated users were unwilling to give any one company too much of their information and would opt to use different browser services. Ghostery and other ad blockers allow users to see who was tracking them. This makes it more difficult for ad networks to effectively monetize. More importantly, it reduces the amount of information companies could track about their users.
Fast Forward to Today…
It is now 2018 and adoption of Ghostery and other tracking systems has grown significantly. Business Insider has this to say:
Adblocker usage surged 30% in 2016 (according to PageFair) …There were 615 million devices blocking ads worldwide by the end of 2016, 62% (308 million) of those mobile. Desktop ad blocker usage grew 17% year-on-year to 236 million.
Dr. Johnny Ryan, PageFair’s Head of Ecosystem concluded:
In 2014 we were dealing with early adopter users of ad blocking. These people really care and understand the real problems of privacy and data leakage in ad tech. I think what happened is the industry’s lack of an approach or interest in privacy let the ad block genie out of the bottle.
More recently, I posted an article on Facebook about the dangers of Google Home in response to this article: The Google Home Mini secretly recorded peoples’ conversations and played into a big fear about smart speakers.
It was clear from this chat that while people were educated about the information they were giving up to Facebook, they were not entirely aware of the extent to which they were sharing.
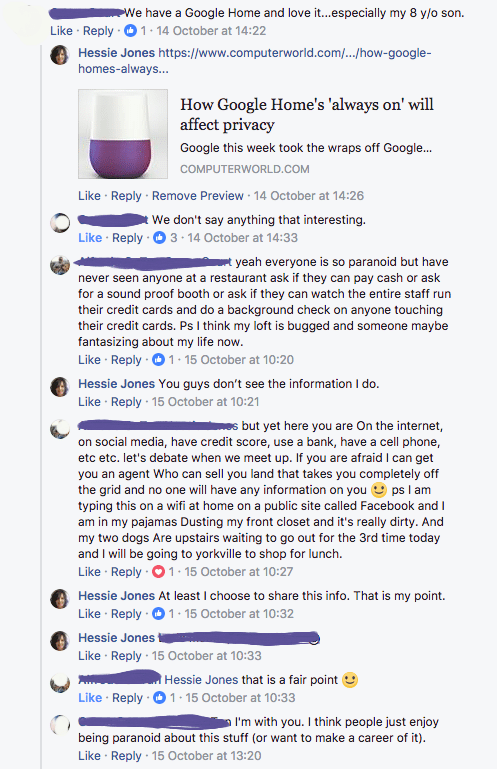
The point I was making was a matter of CHOICE.
It’s NOT that “we may not say anything interesting”.
It’s NOT that people should be paranoid about the things they share in public.
My point was that “what we share” may not necessarily be our choice.
That choice is determined by the platforms. The data they collect –public or private — in and of themselves, provide enough fodder to create more defined social graphs of anyone and everyone.
Recently, HBR Published this article: Customer Data: Designing for Transparency and Trust
They published these stats about consumer awareness of what data is shared. The question is how much is the average consumer aware of what’s being collected? Secondly, if they did know, would they be concerned?

These days, however, there is this idea of fair exchange between the user and companies who collect or analyze data. Consumers expect much better service and more relevant communications by the company in exchange for information they share.
The chart from HBR’s article depicts this notion of fair exchange. The more data a company collects increases the consumer expectation levels. For companies like Facebook, whose primary business includes highly targeted advertising from its data collection of users, the analysis required to profile and predict user propensities ultimately will drive more revenue for the company.
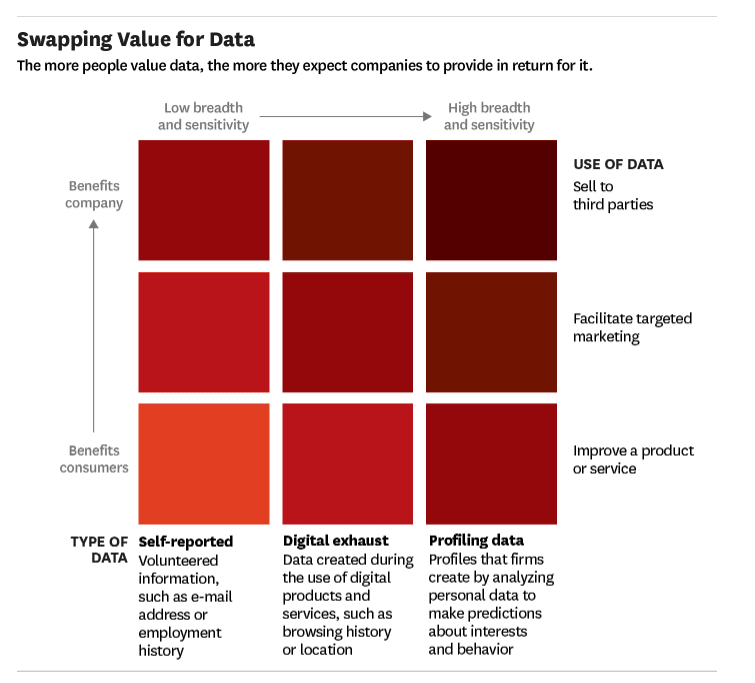
And as this demand grows, the price for increased contextualization at the individual level will also rise. The more a company understands user motivation and user intent, the more they can develop more effective campaigns with the higher prediction of consumer response.
AI: Where Context is EVERYTHING
I work in AI. I see the data. I also see what’s possible. At Humans for AI, I also speak to data scientists who analyze vast amounts of information every day. We are all aware of the advantages and pitfalls of correlating this information.
During my discussion with one of our founding members, Neeraj Sabharwal, also a former big data architect/engineer with Horton Works, he relayed the importance for every consumer to bear responsibility for what each one of us shares on our devices. What we divulge, publicly or privately and how we share this information may be used to extract insights in aggregate or at an individual level. Neeraj noted Venmo users share all of their activity publicly by default unless they choose to share the money transfer in private or friends only. This article by Wired explains in detail how Google tracks you and how you can avoid or reduce the tracking.
Awareness is the key and once we know the data lineage (what, how,
where and who accesses our data) then we can be more conscious of our decisions.
We discussed the work that Elon Musk and Open AI were doing with AI and governance. OpenAI focuses on “Discovering and enacting the path to safe artificial general intelligence. “ As per Musk:
I think AI is probably the single biggest item in the near term that’s likely to affect humanity. So it’s very important that we have the advent of AI in a good way, that it’s something that if you could look into a crystal ball and see the future, you would like that outcome. Because it is something that could go wrong… So we really need to make sure it goes right.
Consider the data is more than what we share on different social networks, our email, our transactions, our customer service chats. It is about the aggregation of information from all these disparate data sources… and correlation of information through AI that has the ability to find patterns with an unprecedented capability. For the first time in history, this combination of data, computing power, increased interconnectivity and advances in pattern analysis are making contextualization entirely possible at (and this can be arguable at this nascent stage) increasing accuracy and precision.
What today’s privacy regulations may not consider is the user’s right to give permission to use the information in a variety of contexts that go beyond customer service or communication implications. This may include:
1) At a personal level — providing health recommendations and notifications, or providing daily task reminders
2) At an aggregated level — helping medical research to better diagnose conditions or preventing potential threats to security.
Information will now evolve beyond what we share on our social networks and to companies. We will be instrumenting our homes, our work, and our bodies with sensor and AR devices. Our quest for increasing convenience through automation may yield unwitting results in the process — the risk of bias, intentional or not.
Facebook’s recent announcement to change the Newsfeed algorithm to prioritize friends and family content over brand promotions shows every indication that Facebook is serious about moving away from its core media business and become a significant data player in this next stage of AI. With the troves of user information it captures, this move solidifies Facebook’s intent to encourage more user behavior in the wake of “content collapse”…
… that is seeing people share less intimate information — and move instead to newer and smaller sites like Snapchat or Instagram to do so.
Contextualization in Play: China’s Social Credit Rating
I’ve been following China’s Sesame Credits for some time. Recently it was announced that China plans to launch its social credit system in 2020. The article entitled, “Big data meets Big Brother as China moves to rate its citizens” is putting into place a platform that probes into the social behavior from its 1.3 billion citizens in an attempt to judge their “trustworthiness”. The scoring system is a dynamic value that rises and falls on individual behavior. Trustworthiness is defined by the Chinese government and it’s a system — worse than prison — that keeps citizens compliant. This form of gamification brings BF Skinner’s Operant Conditioning to life through AI, a punishment and reward system where people’s data are now being used against them.
AI’s nascency is an opportunity to take early control of what we WANT to remain private
Western civilization and our citizens, no doubt, are not immune to massive data collection, aggregation, and analysis at a much granular level. But we do have choices and freedom affords us certain entitlements.
Dr. Ann Covoukian — former Privacy Commissioner of Ontario and now Executive Director of the Privacy and Big Data Institute and leading global advocate for individual privacy has effectively communicated the belief that “privacy and freedom are inextricably linked”. Ann dismisses the “zero-sum” mindset that people must choose between privacy or security, but can’t have both.
She believes that we do not have to forsake individual privacy in order to keep our society safe. If we’ve to move to a common acquiescence of mass surveillance we relinquish our individual freedoms. With the advent of big data, this does not have to be the case.
And this conviction is widely held in Canada, and now with the implementation of the European General Data Protection Regulation (GDPR) coming into force by May 2018, a widespread more harmonized system of data privacy is being enacted. Systems and policies will now be required to proactively enforce this. Please read here about how users will gain much more control over their social data.
Regardless, we all have a responsibility to, as Neeraj alluded to, be accountable for what we share and how we share it. As our children grow up in this world of increasing transparency, they will need to understand the limitations of this new world and ultimately have control over their personal information.
This post originally appeared on Humans for AI and is the subject of discussion for the event in Toronto January 23rd.
2 thoughts on “The Ethics of Artificial Intelligence: What Kind of Society Do We Want to Have?”





Get a Free Consultation
for Content Marketing

Hi Hessie,
Great article! I think you touch on some really important points, especially in relation to what the average consumer realizes is collected and what they don’t know. I’m glad you also brought in the China example at the end, I think when many people watched Black Mirror Season 3 episode 1 they were pretty freaked out–it’s not as sci-fi as we think, and China is an example of the so-called sci-fi coming to life. The data that is collected is opaque and the way it effects individuals will remain to be seen in the long-term.
Although China’s system may be more overt, I would check out “Weapons of Math Destruction” by Cathy O’Neil. It’s an interesting analysis on big data systems in the USA, and might question the assumptions, “western civilization and our citizens…but we do have the choices and freedom affords us certain entitlements.”
Again great article! Wish I could be in Toronto to attend the event.
Hi Jess! You’ve read my mind! I read Weapons of Math Destruction over the holidays and it confirmed my fears about inherent biases already in our system that need to be re-engineered! I’ve just started watching Black Mirror and I’m in Season 1. We have the recipe to do advanced social scoring to gain more context and predictions on individual behaviour — but more importantly it’s about control, which is even scarier. Thanks for commenting! I’ll be posting the video of the event afterwards!